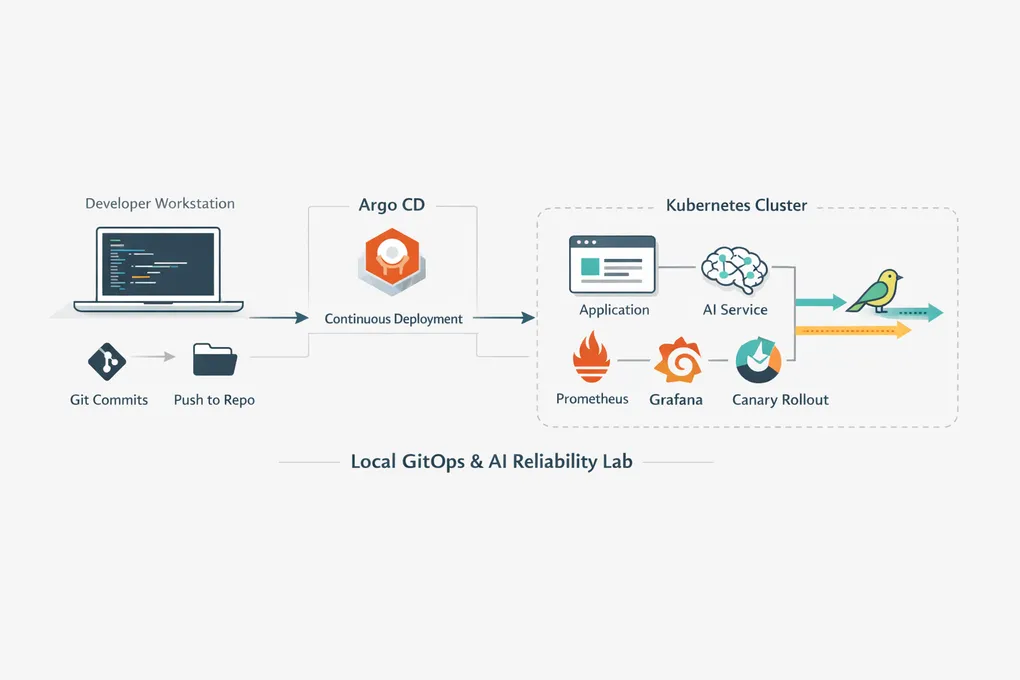
Why I Built A Local GitOps And AI Reliability Lab
Sometimes the best way to learn a system is to give yourself a problem that is just a little larger than your current comfort zone.
That is what this repository became for me.
At the start, the motivation was fairly simple: I wanted to get sharper on Argo CD and GitOps in a way that went beyond reading docs or following a polished tutorial. I wanted something local, something I could break, something I could recover, and something that would force me to think about what actually happens before merge, after merge, and during failure.
But I also wanted the exercise to be a little more interesting than “deploy a demo app and call it done.” So the lab gradually picked up a second purpose: use a small AI-backed service as the thing being delivered, observed, evaluated, and promoted.
That combination ended up being much more useful than I expected.
Why Argo CD
Argo CD sits in one of those places in the stack that sounds conceptually simple until you actually have to operate around it.
The clean version of the story is easy to say:
- Git is the source of truth
- Argo CD reconciles cluster state to Git
- drift gets corrected
- deployments are visible and auditable
That is all true, but the interesting questions start immediately after that:
- what fields should be allowed to drift?
- what should reconcile immediately?
- what should be caught in CI instead of after deploy?
- what happens when Argo’s own control plane is unhealthy?
- how do rollout controllers and autoscalers coexist with Git reconciliation?
Those are much better learning questions than “can I get the Argo UI to come up on localhost?”
So the lab was designed to answer them in a hands-on way:
- bootstrap a local cluster
- manage workloads through Argo CD
- make changes only through Git
- add observability
- add failure drills
- deliberately run into the edge cases where controller ownership gets messy
That produced much better understanding than a passive walkthrough ever would have.
Why Add An AI Service At All
I did not want the repository to stop at generic Kubernetes mechanics.
A normal web app is useful for proving rollout behavior, probes, observability, and GitOps reconciliation. It is less useful for demonstrating the kind of quality questions that come up once a system is “healthy” but still wrong.
That is where the AI service came in.
The small document-QA service in this repo is intentionally modest:
- deterministic extractive mode by default
- optional generative mode through Gemini
- structured JSON responses
- replayable eval cases
- latency and quality metrics
- canary analysis hooks
- optional LangSmith tracing
This was not about building a flashy chatbot. It was about creating a workload where infrastructure health and application quality are not the same thing.
That distinction matters.
A pod can be ready.
A service can return 200.
A JSON schema can validate.
And the workflow can still be failing in the only way the user actually cares about.
Once that is true, the reliability conversation gets much more interesting.
What I Actually Wanted To Learn
In broad terms, the lab was meant to answer three questions.
1. How Does GitOps Hold Up Under Real Operational Friction?
Not “can it deploy,” but:
- how does it behave with branch protection?
- how does it interact with image builds?
- how does it handle post-merge artifact pinning?
- how does it behave when controllers like HPA or Rollouts legitimately mutate state?
Those questions led to some of the most interesting parts of the project, especially around image pinning and automation identity.
2. What Does “AI Reliability” Look Like In A Small, Honest Demo?
A lot of AI reliability conversation is abstract until you can point at a running system.
This lab gave me something concrete:
- deterministic evals in CI
- optional generative evals outside the deterministic PR path
- workflow completion ratio
- structured-output validity
- insufficient-context behavior
- canary checks tied to service quality rather than only transport health
That made the AI part of the repo feel like a real engineering problem instead of a slide-deck topic.
3. How Do Good Platform Habits Actually Compound?
The repo started simple, but each layer made the next one more valuable:
- Trivy improved the manifests
- smoke tests caught runtime regressions
- diagnostics made failures actionable
- observability made Argo itself visible
- canary promotion became more meaningful once the AI service had real quality signals
- image pinning mattered more once the service became a genuine deployable artifact
That compounding effect is one of the most satisfying things about this kind of work.
What The Lab Became
By the time the repo settled into its current shape, it was doing more than I originally planned:
- Argo CD app-of-apps bootstrap
- Helm-based guestbook deployment
- Prometheus, Grafana, OpenTelemetry Collector, and Blackbox Exporter
- AI doc-QA service with extractive and generative modes
- deterministic evals in CI
- kind-based smoke tests
- Argo Rollouts canary delivery
- HPA-based scaling
- LangSmith traces
- post-merge image build and digest pinning back into Git
- documented failure drills and incident notes
That is a lot for a local lab, but the point was never maximal feature count. The point was to build a system where reliability ideas could be demonstrated, not just asserted.
What Surprised Me
Two things in particular.
The first was how often the most valuable lessons came from small failures rather than big wins.
A rollout timing out, Argo CD fighting an HPA, a config change not reloading cleanly, a GitHub App permission model not behaving the way I assumed it would: those were all better teachers than the parts that worked immediately.
The second was how quickly “a little GitOps practice repo” became a real systems-design exercise.
Once you add:
- CI checks
- progressive delivery
- AI-specific quality signals
- container image promotion
- automation identities
you are no longer doing a toy walkthrough. You are doing the kind of integration work where the interesting part is the boundary between systems.
What I Think The Repo Shows Now
At this point, I think the lab demonstrates something more useful than “I can stand up Argo CD locally.”
It shows:
- how I think about reliability as part of the delivery path, not an afterthought
- how I like to make failures observable and diagnosable
- how I approach AI systems as quality-sensitive workflows, not just HTTP services
- how I reason through tradeoffs when the cleanest theoretical design is not the most supportable practical one
That last point may actually be the most important. A lot of the value here came from discovering where the elegant version of an idea stopped being worth the cost.
Why I’m Glad I Built It
This repo started as a learning exercise.
It ended up becoming a much better artifact than that:
- a place to deepen Argo CD intuition
- a place to explore GitOps delivery under realistic constraints
- a place to practice AI reliability in a small but concrete system
- a place to document lessons that I suspect I will reuse elsewhere
That feels like a good outcome.